The TL;DR: Divergent-Convergent Attention (DCA) improves compositional reasoning by maintaining multiple parallel attention perspectives before periodic learned consensus. On HotpotQA1, DCA achieves 5.4x higher exact match than a parameter-matched 90M baseline, and a 215M DCA model outperforms a 355M standard transformer by 1.54x with fewer parameters and lower memory.
Most notably, DCA assigns higher probability to the correct answer tokens on 98% of examples, with the advantage sharply correlated with question difficulty, suggesting that DCA’s magic is in how distributed evidence is internally composed before decoding.
(Note: This blog post is the current preprint version of this work.)
Introduction
Standard transformers process multi-document input through a single attention stream, fusing heterogeneous evidence into one representation at every layer. RAG pipelines, long-context windows, and tasks like legal analysis or medical synthesis all require integrating information from structurally independent sources. A single stream must compromise between local precision and global reach at every layer. The result is premature fusion, where multi-document evidence is collapsed before the model can develop complementary views.
We introduce Divergent-Convergent Attention (DCA), a transformer variant that maintains K parallel attention streams at different scales and reconciles them only at scheduled consensus points. The novelty is not merely independent lanes or a late merge, but that those lanes are explicitly multi-horizon: short, medium, and long timescales that cultivate complementary perspectives before reconciliation.
DCA is inspired by an organizational principle in neuroscience: the brain concurrently maintains multiple oscillatory bands that only periodically couple to coordinate information23. Gamma (30-100 Hz) supports fast, local feature binding, analogous to our short horizon. Beta (13-30 Hz) integrates across nearby regions, our medium horizon. Alpha/theta (4-13 Hz) supports global synchronization, our long horizon45. DCA provides the computational analogue: separate processing streams that periodically synchronize via learned consensus.

Figure 1a Biological multi-scale oscillations. Gamma, beta, and theta bands process at different scales and periodically couple to coordinate information. DCA maps these to three attention horizons.
In controlled experiments, DCA achieves 5.4x higher exact match on multi-hop QA at 90M parameters (p<10^-6, 3 seeds). At 215M, DCA beats a 355M baseline by 1.54x with fewer parameters, approximately matched FLOPs, and less memory. We characterized the consensus mechanism through causal interventions at both scales. Despite the small capacity of these models, our force-decode analysis shows an unambiguous representational advantage in multi-document composition. DCA assigns higher probability to the correct answer tokens on 98% of all examples, and the advantage scales with difficulty, with 8x larger gains on the hardest examples.
The Architecture
Multi-scale transformers and routing models typically blend scales early or continuously, collapsing independence before perspectives can specialize. Efficient attention methods (Longformer, BigBird, ring attention) address computational scaling but not when heterogeneous evidence should be fused. MoE architectures increase capacity through sparse routing but do not enforce temporal specialization or late fusion.
In contrast, DCA replaces each transformer block with K parallel attention streams (“perspectives”), each operating at a different window size. In our experiments, K=3 with horizons [32, 128, 0], where 0 denotes full causal attention. Each perspective has its own QKV projection weights. All perspectives share a single MLP, with all paths always active (closer to ResNeXt’s split-transform-merge6 than to Mixture of Experts’ selective routing7, and analogous to cross-scale pooling in multi-scale vision transformers8). Every N layers, the perspectives merge via a Highway Network-style gate9, a periodic synchronization analogous to federated averaging10. This gate is content-dependent and learned, and the model discovers a depth-dependent strategy where early layers mostly pass through and late layers merge more fully (Section 4).
consensus = mean(perspective_1, ..., perspective_K)
gate = sigmoid(W_g * RMSNorm(x))
output = (1 - gate) * x + gate * consensus
Note that while the implementation described here uses dense causal attention, DCA is actually a more general late-consensus primitive. The consensus mechanism operates on tensors so any module that takes [B, T, D] and produces [B, T, D] can serve as a perspective. In this work, we use dense causal attention with different window sizes, but other sequence-processing modules (ring attention, linear attention, SSMs) could serve the same role.

Figure 1b DCA architecture. K=3 perspectives fork from the residual stream, process independently at different window sizes, then merge via learned highway consensus. The cycle repeats every N layers.
Benchmarks
HotpotQA at 90M (WikiText-103)
Which film received more Academy Award nominations, Zero Dark Thirty or Arrival?
Figure 2 HotpotQA distractor setting. 10 paragraphs per question: 2 supporting (green), 8 distractors (gray). The answer requires composing information from both gold paragraphs scattered among topically similar distractors.
We pretrained DCA (89M params) and a parameter-matched baseline (90M params) on WikiText-10311 for 50K steps, then finetuned both on HotpotQA across three seeds. Though DCA is modestly worse on WikiText-103 validation perplexity (21.48 vs 20.79, ~3%), the benefit on long reasoning is asymmetric. DCA achieves 5.4x higher exact match on HotpotQA (1.56% vs 0.29%, Table 1), with p<10^-6 and odds ratio 5.49 (Fisher exact, pooled across seeds). Every DCA variant beats every baseline across both 12-layer and 6-layer scales and across 50K and 30K pretrain budgets without exception.
Scaling to PG-19 and architectural exploration
The 90M result raises a natural question: does the advantage hold at larger scale? While the relative advantage is clear, absolute performance of both models is low (1.56% and 0.29% EM). As no published decoder-only HotpotQA results exist between 90M and 7B (Appendix), we scaled up into the ~350M regime. WT103 is too small for 350M-class models, so we switched to PG-1912 (3B tokens) following standard conventions (GPT-3 Medium13: lr=3e-4, eff_batch=128).
To calibrate the effect of pretraining domain, we also trained DCA 90M on PG-19 (EM=0.38%, compared to 1.56% on WT103). The 350M standard baseline on PG-19 achieves 0.93% EM, indicating that even at 4x the parameters, standard decoders remain poor at multi-hop QA. A FLOP-comparable DCA-215M on PG-19 achieves 1.43% EM vs the baseline’s 0.93% (1.54x), with 39% fewer parameters and less VRAM (~35 vs ~45 GB). Within PG-19, scaling DCA from 90M to 215M improves EM from 0.38% to 1.43%, surpassing the 350M baseline by 1.54x.
Table 1: HotpotQA results across scales and pretraining domains. All models finetuned and evaluated on HotpotQA.
WT103 pretraining (90M):
| Model | Params | FLOP ratio | VRAM | EM% | F1% |
|---|---|---|---|---|---|
| Baseline 90M | 90M | ~1.0x | ~4 GB | 0.29 | 7.84 |
| DCA 90M | 89M | ~1.56x | ~8 GB | 1.56 | 14.40 |
PG-19 pretraining (up to 350M):
| Model | Params | FLOP ratio | VRAM | EM% | F1% |
|---|---|---|---|---|---|
| DCA 90M | 89M | ~1.56x | ~8 GB | 0.38 | 7.78 |
| Baseline 350M | 355M | 1.0x | ~45 GB | 0.93 | 10.81 |
| DCA-215M | 215M | 1.24x | ~35 GB | 1.43 | 11.32 |
Architectural exploration
Scaling also provided an opportunity to test which components of DCA are essential and explore practical tradeoffs. The biggest disadvantage of full-fat DCA at baseline width (K=3 at d=1024) is cost: 3x VRAM and ~2.7x FLOPs. A narrower variant at d=768 (323M params) achieved only EM=0.57%, undertrained at 6.2 tokens per parameter because FLOP matching compressed it to 15K steps. A variant without per-perspective MLP (302M params, 1.07x FLOPs) achieved EM=1.21% (1.30x over baseline), indicating the per-perspective MLP is important for the mechanism. Separate MLP weights (139M params, same FLOPs) achieved PPL=20.45 (beating baseline for the first time) but EM=0.80%, half the shared MLP’s 1.56%, confirming the shared MLP acts as a regularizer.
We also evaluated DCA’s core architectural hypothesis. The natural alternative to parallel streams is per-head window assignment. We tested this (baseline_mixed: heads 0-2 at w=32, heads 3-5 at w=128, heads 6-7 full causal). It achieves the best perplexity of any model (20.79) but only 0.29% EM on HotpotQA. A factorial experiment confirmed parallel streams are the primary mechanism; multi-scale windows are secondary. Two other architectural properties proved essential. Shared QKV weights collapse perspective diversity (cosine similarity 0.95 vs 0.14 with separate weights). Consensus at every layer (k=1) drops EM to 1.05% vs 1.59% with consensus every 6 layers (k=6). This suggests that perspectives need both separate weights to specialize and time between consensus points to diverge.
These results are what motivated the aforementioned DCA-215M design. Bottleneck projections let perspectives operate at d_lane=512 inside d_model=1024. Since 3 x 512^2 < 1024^2, K=3 perspectives at d=512 are cheaper per layer than a single stream at d=1024. This replaces the role that global tokens play in Longformer and BigBird1415 in a causal-compatible way. Global tokens in causal decoders are functionally vacuous since position 0 can only attend to itself. Per-perspective gradient checkpointing reduces activation memory from ~3x baseline to below baseline levels. We scale by adding layers (30L) at the cheap d=512 perspective width rather than widening to d=1024.
Table 2: DCA design space. Theoretical and tested variants with FLOP and VRAM tradeoffs.
| Variant | d_model | d_lane | Params | FLOP ratio | VRAM vs baseline | MLP every layer? |
|---|---|---|---|---|---|---|
| Standard baseline | 1024 | – | 355M | 1.0x | 1.0x | Yes (1 stream) |
| Full-fat (d=1024, K=3) | 1024 | 1024 | 556M | 2.71x | ~3x (OOM) | Yes (K calls, shared) |
| DCA-215M (bottleneck) | 1024 | 512 | 215M | 1.24x | ~0.8x | Yes (K calls, shared) |
| DCA-215M + separate MLPs | 1024 | 512 | 341M | 1.24x | ~0.8x | Yes (K calls, K weights) |
Table 3: Architectural variant results. All evaluated on HotpotQA.
| Model | Params | d_model | d_lane | EM% | VRAM |
|---|---|---|---|---|---|
| DCA 90M (full-fat) | 89M | 512 | 512 | 1.56 | ~8 GB |
| DCA-d768 | 323M | 768 | 768 | 0.57 | ~45 GB |
| DCA-noMLP | 302M | 1024 | 768 | 1.21 | ~35 GB |
| DCA-215M (bottleneck) | 215M | 1024 | 512 | 1.43 | ~35 GB |
| DCA 90M (separate MLPs) | 139M | 512 | 512 | 0.80 | ~10 GB |
The DCA-215M results (Tables 1 and 3) confirm this design is practical and competitive.
What is DCA well suited for?
HotpotQA is a distributed-source task: relevant information is scattered across independent paragraphs among distractors. Does the advantage generalize to other task structures? We tested 10+ additional benchmarks at 90M to probe where DCA helps and where it does not (detailed numbers in Appendix).

Figure 3 Information topology. DCA helps when relevant content is distributed across independent documents (left). It does not help when information forms a single chain (right).
Sequential reasoning tasks (bAbI16, Tree pathfinding17, PrOntoQA18, LEGO19) show no advantage; all facts lie in a single flat sequence and every attention scale sees the same chain. Single-source tasks (TriviaQA20, LAMBADA21, MQAR22) show no advantage; all perspectives see the same content. Tasks beyond model capacity (MuSiQue23) show both models at floor. 2WikiMultiHopQA24 provides weak corroboration (Soft EM p=0.004, EM ns).
DCA helps when relevant information is distributed across structurally independent segments, what we refer to as the information topology of the input, and does not help when information forms a single chain or resides at a single location. Within HotpotQA, the advantage is uniform across bridge questions (sequential logic, OR=4.65) and comparison questions (parallel logic, OR=4.51), indicating that multi-document context, not reasoning pattern, is the key factor. DCA’s advantage is stronger on single-support examples (OR=4.95) than multi-support (OR=3.02), suggesting the benefit is partly about navigating distractors, not just composing across multiple sources.
Mechanistic Analysis
Force-decode: the representation advantage
To separate representation quality from generation dynamics, we feed the context to both models and force-decode the gold answer tokens (teacher-forcing), recording each model’s log-probability of the correct token at each position. If a model’s representations encode the answer well, it will assign high probability to the gold tokens regardless of whether it generates them correctly during free generation. For each of 6,359 validation examples, we compare which model assigns higher probability to the gold answer. This is a paired comparison across all examples, not just the small fraction where EM=1.
Table 4: Force-decode results. Paired comparison across all 6,359 HotpotQA validation examples. Wilcoxon signed-rank p < 10^-300 at both scales.
| 90M DCA vs 90M baseline | 215M DCA vs 350M baseline | |
|---|---|---|
| DCA assigns higher probability | 97.8% (6,217/6,359) | 98.3% (6,248/6,359) |
| Average advantage | +6.25 nats (~520x) | +8.76 nats (~6,400x) |
The nats advantage translates to probability: +8.76 nats means DCA assigns roughly 6,400x higher probability to the correct token at each position on average (nats use natural log; e^8.76 ≈ 6,400). The representation advantage is near-universal and strengthens as param count doubles, implying structural benefits intrinsic to DCA that might also manifest in EM should we scale up further. At 215M, a model with 39% fewer parameters produces better internal representations than the baseline on 98.3% of examples. Notably, advantage is also correlated with baseline difficulty. We binned examples by how well the baseline encodes the gold answer (baseline log-prob quintiles) and measured DCA’s advantage in each bin (r=-0.896).
Table 5: Force-decode advantage by baseline difficulty quintile (215M).
| Baseline difficulty percentile | Mean DCA advantage | DCA win rate |
|---|---|---|
| 0-20% (easiest) | +2.29 nats | 96.9% |
| 20-40% | +4.84 nats | 98.3% |
| 40-60% | +7.28 nats | 96.2% |
| 60-80% | +10.80 nats | 99.8% |
| 80-100% (hardest) | +18.58 nats | 100% |
DCA helps on every quintile, but the advantage is 8x larger on the hardest examples than the easiest (Table 5, Figure 4). The harder an example is for a standard transformer, the more DCA’s multi-perspective consensus improves the representation.

Figure 4 DCA-215M vs Baseline 350M (both PG-19). DCA’s representational advantage scales with example difficulty. On the hardest quintile (where the baseline assigns the lowest probability to the correct answer), DCA’s advantage is +18.58 nats. On the easiest, +2.29 nats. r=-0.896.
Same retrieval, better composition
Next, we investigated if and how DCA’s superior representations manifest in the model’s output. We measured Token Recall and Token Precision on generated predictions (90M, WT103) to differentiate between retrieval and composition. Token Recall (fraction of gold answer tokens appearing anywhere in the prediction) is identical at 57.5% for both models. Token Precision (fraction of the prediction consisting of gold tokens) shows the full advantage: 8.2% vs 4.3% (1.9x). DCA does not find more information, but rather composes the same information more precisely.
Figure 5 DCA 90M vs Baseline 90M (both WT103). Token Recall is identical (57.5%). The entire advantage is in Token Precision (8.2% vs 4.3%).

First-sentence extraction decomposes this further. By taking only the first sentence of each model’s output, we isolate the initial answer attempt from subsequent generation quality. Compositional integration (~1.2-1.5x) is the advantage that survives this extraction, reflecting cleaner internal representations at the point of first output. Generation coherence (~2-3x) is the additional advantage from maintaining quality over subsequent tokens, where the baseline degenerates into repetition, and it scales with answer length (3x at 1 token, 12.8x at 4+ tokens). This decomposition also explains the null results on single-source tasks like TriviaQA and LAMBADA: when all relevant information is at a single location, all perspectives see the same content and consensus has nothing to integrate.
Gate ablation: consensus is essential and precisely tuned
We force the consensus gate to fixed values during full QA evaluation using forward hooks. Gate=0 clamps the sigmoid to 0.001 (bypass consensus). Gate=1 clamps to 0.999 (force full consensus).
Table 6: Gate ablation results. Forcing gate to fixed values during full QA evaluation.
| Condition | 90M correct | 215M correct |
|---|---|---|
| Learned gates | 101 | 91 |
| Gate=1 (force full) | 18 | 0 |
| Baseline | 12 | 12 |
| Gate=0 (bypass) | 2 | 2 |
Bypassing consensus (gate=0) collapses performance from 101 to 2 correct at 90M and 91 to 2 at 215M (Table 6), so consensus is clearly essential. In contrast, forcing full consensus (gate=1) tells a more nuanced story. At 90M it drops from 101 to 18, while at 215M it drops from 91 to 0. This is consistent with the 215M model’s learned gate pattern (max 0.37) being far from 1.0, so forcing gate=1 is a much larger deviation.
The learned gate values reveal two distinct strategies at the two scales (Table 7):
Table 7: Learned gate values at consensus layers.
| Consensus layer | 90M gate | 215M gate |
|---|---|---|
| Layer 5 (1st) | 0.29 | 0.31 |
| Layer 11 (2nd / final at 90M) | 0.99 | 0.21 |
| Layer 17 (3rd) | – | 0.28 |
| Layer 23 (4th) | – | 0.35 |
| Layer 29 (5th / final) | – | 0.37 |
At 90M the strategy is binary: passthrough early, full commit at the final layer. At 215M it is gradual and never exceeds 0.37. Both strategies are load-bearing, and disrupting either destroys performance. This validates the convergent half of the DCA thesis, that periodic late consensus is not just beneficial but necessary.
Perspective divergence and attention patterns
Next, we evaluated whether the perspectives actually develop distinct, complementary representations. Perspectives develop genuinely distinct representations (cosine similarity 0.21 between local and medium at layer 5), meaning the perspectives are complementary rather than redundant.
Figure 6 DCA 90M vs Baseline 90M (both WT103), consensus layer 5. Each DCA perspective operates at a different scale. The baseline settles on a single-stream value in between.

Attention measurements confirm the specialization. The local perspective keeps 96% of attention within paragraphs (cross-document fraction 0.04), while the global perspective distributes 68% across documents. In contrast, the dense transformer baseline sits at 0.34. With DCA, local perspectives extract precise within-document content, global perspectives maintain cross-document context, and consensus integrates both. The baseline cannot simultaneously attend locally and globally, and is forced to compromise. Together, the gate ablation and attention analyses demonstrate that DCA’s diverse perspectives specialize by scale and combine through learned periodic consensus to produce superior representations for long reasoning.
Discussion
Multi-document composition is a documented bottleneck for production LLMs. RAG pipelines retrieve relevant documents but fail to synthesize across them25. Models fail to use information in the middle of long contexts26. Multi-hop reasoning requires 30-70B parameters to emerge in standard transformers27. With DCA, we sought to demonstrate that parallel multi-scale perspectives with periodic late consensus can improve on these deficiencies.
Despite the limited capacity of our models, extensive benchmarking demonstrated a consistent advantage on distributed-source tasks (5.4x EM at 90M, 1.54x at 215M FLOP-comparable) and no advantage on sequential, single-source, or capacity-limited tasks. Investigation of the mechanism revealed that both the late consensus gate and diversity in perspective specialization are essential features of DCA’s architecture. The resulting representations encode multi-document relationships better than a standard transformer on 98% of examples, with 8x larger gains on the hardest examples, reflecting an advantage in composition rather than simply retrieval. DCA’s demonstrated strength on distributed-source tasks aligns with the aforementioned failure modes of contemporary LLMs.
Open questions and future directions
We believe this work represents an exciting start, but there are still many avenues for further exploration. Consensus frequency, horizon widths, and gate training dynamics were fixed throughout our experiments and could conceivably be tuned for better performance or task-specific behavior. As noted earlier, DCA is fundamentally an architectural primitive that operates on tensors, so other sequence-processing modules (ring attention, linear attention, SSMs) could serve as perspectives. The force-decode diagnostic is itself useful beyond DCA and could be applied to evaluate other architectures, revealing whether the bottleneck in a given model is understanding or expression. We will be sharing the base code for DCA on GitHub and encourage interested researchers to reach out with questions or share their results.
Appendix
Force-decode difficulty scaling
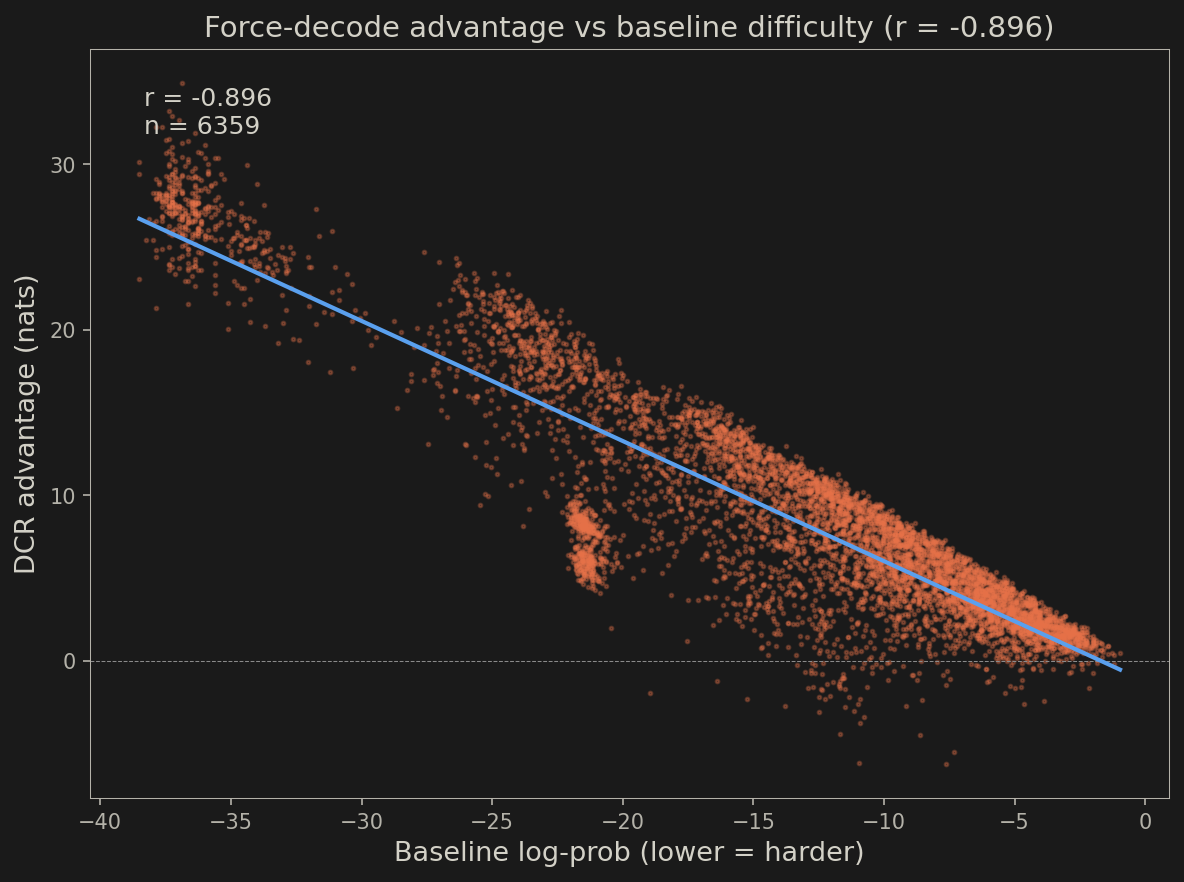
Appendix Figure Per-example force-decode advantage (DCA log-prob minus baseline log-prob) plotted against baseline log-prob (215M DCA vs 350M baseline). Each point is one of 6,359 HotpotQA validation examples. r=-0.896. The harder an example is for the baseline (more negative log-prob), the larger DCA’s representational advantage.
Published “mid-size” decoder-only models
| Architecture | Params | HotpotQA EM | Notes |
|---|---|---|---|
| DCA 90M | 89M | 1.56% | Decoder-only, WT103, fine-tuned |
| Baseline 90M | 90M | 0.29% | Decoder-only, WT103, fine-tuned |
| Baseline 350M | 355M | 0.93% | Decoder-only, PG-19, fine-tuned |
| DCA-215M | 215M | 1.43% | Decoder-only, PG-19, FLOP-comparable |
| BERT-base (encoder) | 110M | ~54% | Bidirectional + span extraction head |
| Longformer-large (encoder) | 149M | F1=74% | Local + global attention |
| BigBird-ETC (encoder) | 131M | F1=76% | Sparse attention |
| RoBERTa-large (encoder) | 355M | ~70% | Near SOTA for encoder-only |
| Llama-2-7B (decoder) | 7B | ~30% | Fine-tuned (FireAct, Chen et al. 2023) |
| GPT-3.5 (decoder) | 175B | ~31% | Few-shot ReAct prompting |
| Human | – | ~91% (F1) | HotpotQA leaderboard |
No published decoder-only HotpotQA results exist between 90M and 7B parameters. Encoder models such as BERT28, Longformer14, BIGBIRD-ETC15, and RoBERTa29 dominate at 110M-355M because HotpotQA was designed for BERT-era extractive QA with bidirectional attention and span extraction heads. Decoder-only models need 7B+ for ~30% EM (FireAct with Llama-2-7B30). Steele & Katz27 identify a phase transition at 30-70B for “emergent multi-hop reasoning.”
Citation
This blog post serves as the current preprint version of this work. Until an archival version is available, please cite it as:
@misc{zhao2026dca,
author = {Ben Zhao and Jenhan Tao},
title = {Divergent-Convergent Attention: Parallel Perspectives for Compositional Reasoning},
year = {2026},
howpublished = {\url{https://iluvatarlabs.github.io/blog/2026/03/divergent-convergent-attention/}},
note = {Iluvatar Labs blog preprint}
}
Acknowledgements
We thank Abel Chiao for helpful discussions and feedback on this work.
-
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., & Manning, C. D. (2018). “HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering”. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018). arXiv:1809.09600 ↩
-
Buzsaki, G. (2006). Rhythms of the Brain. Oxford University Press. ↩
-
Canolty, R. T., & Knight, R. T. (2010). “The Functional Role of Cross-Frequency Coupling”. Trends in Cognitive Sciences, 14(11), 506-515. ↩
-
Lisman, J. E., & Jensen, O. (2013). “The Theta-Gamma Neural Code”. Neuron, 77(6), 1002-1016. ↩
-
Colgin, L. L., Denninger, T., Fyhn, M., Hafting, T., Bonnevie, T., Jensen, O., Moser, M.-B., & Moser, E. I. (2009). “Frequency of Gamma Oscillations Routes Flow of Information in the Hippocampus”. Nature, 462, 353-357. ↩
-
Xie, S., Girshick, R., Dollar, P., Tu, Z., & He, K. (2017). “Aggregated Residual Transformations for Deep Neural Networks”. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017). arXiv:1611.05431 ↩
-
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer”. Proceedings of the 5th International Conference on Learning Representations (ICLR 2017). arXiv:1701.06538 ↩
-
Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., & Feichtenhofer, C. (2021). “Multiscale Vision Transformers”. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2021). arXiv:2104.11227 ↩
-
Srivastava, R. K., Greff, K., & Schmidhuber, J. (2015). “Highway Networks”. arXiv:1505.00387 ↩
-
McMahan, H. B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017). “Communication-Efficient Learning of Deep Networks from Decentralized Data”. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS 2017). arXiv:1602.05629 ↩
-
Merity, S., Xiong, C., Bradbury, J., & Socher, R. (2017). “Pointer Sentinel Mixture Models”. Proceedings of the 5th International Conference on Learning Representations (ICLR 2017). arXiv:1609.07843 ↩
-
Rae, J. W., Potapenko, A., Jayakumar, S. M., & Hillier, C. (2020). “Compressive Transformers for Long-Range Sequence Modelling”. Proceedings of the 8th International Conference on Learning Representations (ICLR 2020). arXiv:1911.05507 ↩
-
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., et al. (2020). “Language Models are Few-Shot Learners”. Advances in Neural Information Processing Systems 33 (NeurIPS 2020). arXiv:2005.14165 ↩
-
Beltagy, I., Peters, M. E., & Cohan, A. (2020). “Longformer: The Long-Document Transformer”. arXiv:2004.05150 ↩ ↩2
-
Zaheer, M., Guruganesh, G., Dubey, A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., & Ahmed, A. (2020). “Big Bird: Transformers for Longer Sequences”. Advances in Neural Information Processing Systems 33 (NeurIPS 2020). arXiv:2007.14062 ↩ ↩2
-
Weston, J., Bordes, A., Chopra, S., & Mikolov, T. (2015). “Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks”. arXiv:1502.05698 ↩
-
Brinkmann, J., Goswami, K., & Rajani, N. F. (2024). “A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task”. Findings of the Association for Computational Linguistics: ACL 2024. ↩
-
Saparov, A., & He, H. (2023). “Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought”. Proceedings of the 11th International Conference on Learning Representations (ICLR 2023). ↩
-
Zhang, Y., Yu, A. W., & Xu, W. (2022). “Unveiling Transformers with LEGO: A Synthetic Reasoning Task”. arXiv:2206.04301 ↩
-
Joshi, M., Choi, E., Weld, D. S., & Zettlemoyer, L. (2017). “TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension”. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017). arXiv:1705.03551 ↩
-
Paperno, D., Kruszewski, G., Lazaridou, A., Pham, N. Q., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., & Fernandez, R. (2016). “The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context”. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016). arXiv:1606.06031 ↩
-
Arora, S., Eyuboglu, S., Timalsina, A., Johnson, I., Poli, M., Rudra, A., & Zou, J. (2023). “Zoology: Measuring and Improving Recall in Efficient Language Models”. arXiv:2312.04927 ↩
-
Trivedi, H., Balasubramanian, N., Khot, T., & Sabharwal, A. (2022). “MuSiQue: Multihop Questions via Single-hop Question Composition”. Transactions of the Association for Computational Linguistics, 10, 539-554. arXiv:2108.00573 ↩
-
Ho, X., Nguyen, A.-K. D., Sugawara, S., & Aizawa, A. (2020). “Constructing a Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps”. Proceedings of the 28th International Conference on Computational Linguistics (COLING 2020). arXiv:2011.01060 ↩
-
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuttler, H., Lewis, M., Yih, W.-t., Rocktaschel, T., Riedel, S., & Kiela, D. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. Advances in Neural Information Processing Systems 33 (NeurIPS 2020). arXiv:2005.11401 ↩
-
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). “Lost in the Middle: How Language Models Use Long Contexts”. Transactions of the Association for Computational Linguistics, 12, 157-173. arXiv:2307.03172 ↩
-
Steele, B., & Katz, M. (2026). “Scaling Trends for Multi-Hop Contextual Reasoning in Mid-Scale Language Models”. arXiv:2601.04254 ↩ ↩2
-
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019). arXiv:1810.04805 ↩
-
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). “RoBERTa: A Robustly Optimized BERT Pretraining Approach”. arXiv:1907.11692 ↩
-
Chen, B., Monajatipoor, M., Veen, D. V., Guo, Y., & Dubrawski, A. (2023). “FireAct: Toward Language Agent Fine-tuning”. arXiv:2310.05915 ↩