The TL;DR: Elastic speculation speeds up inference while maintaining output quality, resulting in more responsive models and a reduction compute costs.
Specifically, adaptive draft length delivers 20-50% latency reduction over fixed-length speculation. Confidence-based early exit cuts speculative KV writes by ~50% at a 1-3% latency cost. Both methods preserve semantic quality at multiple scales (BERTScore >0.9, cosine similarity >0.95, equivalent reward model scoring).
Introduction
Large language model inference is fast enough to demo and slow enough to hurt.
Speculative decoding1 is an incredibly effective strategy for speeding up inference: a smaller draft model proposes multiple tokens, a larger target model verifies them, and we commit the accepted prefix and discard the rest. Implementations like EAGLE2 in vLLM3 already make this practical and widely used.
However, two parts of this pipeline are still potentially inefficient:
- The draft length is fixed, even as acceptance behavior changes across prompts, positions, and workloads.
- Every speculative token writes to KV cache, even when it was never likely to survive verification.
In this post, we introduce Elastic Speculation: a small control layer on top of EAGLE that makes speculative decoding adaptive instead of static.
Why spec decode leaves performance on the table
First, acceptance is not constant and so a global, fixed K is too blunt. For easy or highly structured workloads (e.g., coding or QA-style prompts), acceptance can be very high, so a small K underutilizes the draft model. For harder or more creative workloads, acceptance drops, so a large K wastes compute on tokens that will be thrown away.
Second, being KV-cache bandwidth constrained hurts. Even speculative tokens that will never be accepted still pay the full price of KV writes. At larger batch sizes, longer contexts, and bigger models, KV-cache traffic becomes a dominant bottleneck4. Reducing unnecessary KV work is often the real lever for throughput.
Elastic Speculation treats speculative decoding as a runtime control problem:
- Speculate more when speculation is working.
- Speculate less when it isn’t.
- Stop writing KV for tokens that are very unlikely to matter.
We do this without changing model weights or the verification rule. Our reference implementation is for EAGLE in vLLM, but the same control-plane ideas apply to other speculative decoding methods.
| Elastic Speculation Overview |
|---|
 |
Figure 1 illustrates this design: speculative decoding with a dynamic K, plus a separate control that can gate KV writes.
Adaptive draft length: making K elastic
Our first contribution is enabling an adaptive draft length. Instead of choosing K once and hard-coding it, we let the system adjust K dynamically based on how speculation has been performing recently.
At a high level, our implementation features the following:
- A runtime maintains lightweight statistics about speculative behavior.
- A controller selects a draft length from a small set (e.g., 5, 10, 15) for each step:
- When recent speculative proposals are mostly accepted, it chooses a longer draft.
- When they are frequently rejected, it chooses a shorter one.
- The selected draft length is carried through existing batch descriptors into the EAGLE path. No extra RPC layer, no changes to the verification contract.
Latency savings
We evaluated adaptive draft length on Llama-3.1-8B-Instruct target and draft models, across various configurations (including batch, tokens, etc.) and datasets. We selected the following four diverse benchmark datasets representing different LLM workload characteristics:
Alpaca- Instruction-following tasks spanning creative writing, QA, and general task completion. Representative of typical chat assistant workloads.SQuAD- Reading comprehension requiring extractive answers. Short, factual outputs with high determinism ideal for testing speculation on low-entropy tasks.CNN DailyMail(aka long) - Document summarization, essays, and narratives requiring 256+ tokens. Stresses sustained speculation quality over extended generations.BigCodeBench(aka coding) - Code completion, bug fixing, and algorithm implementation. Highly structured outputs with strict syntactic constraints test adaptive tuning limits.
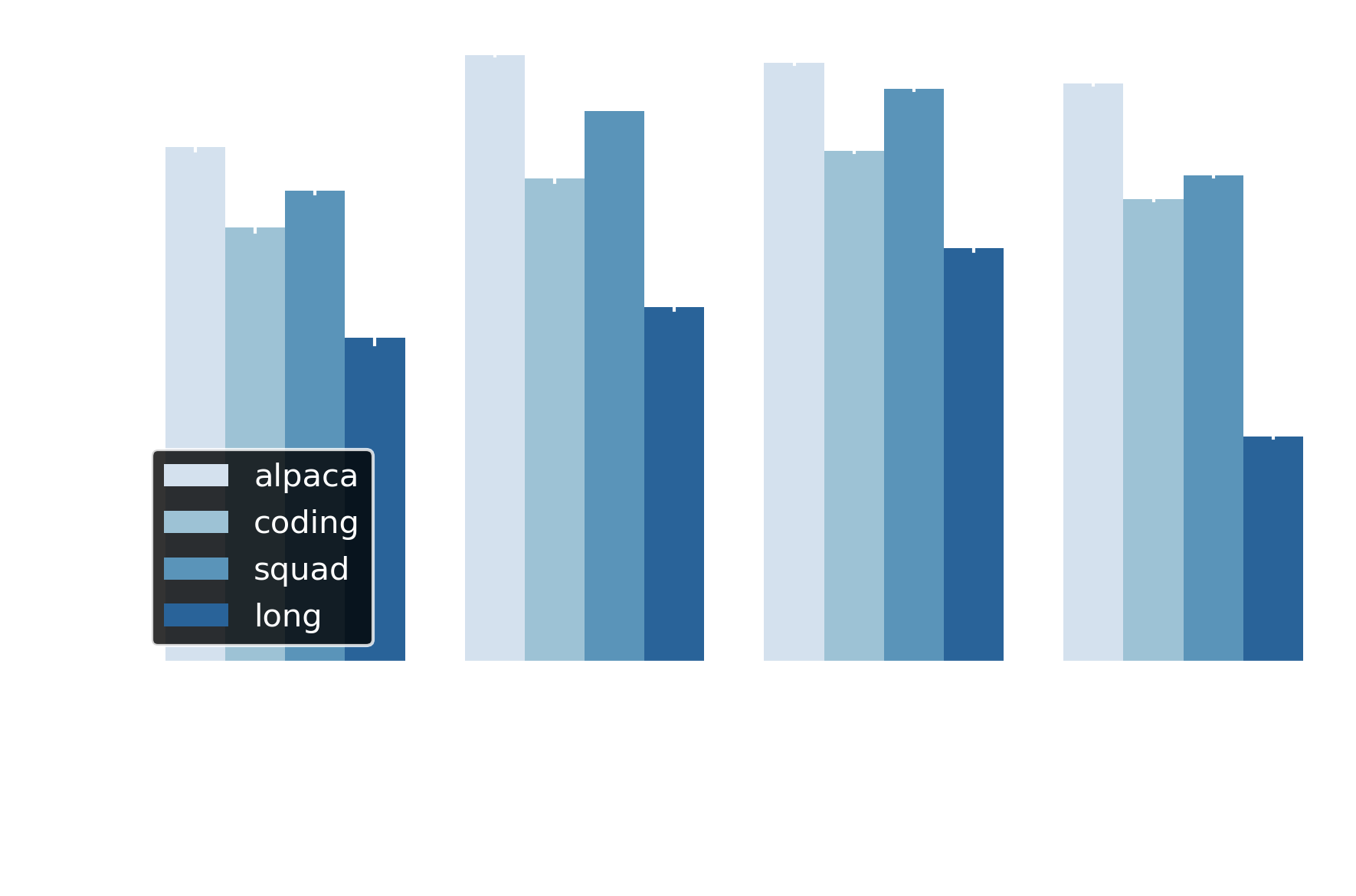
Across workloads ranging from short bursts (12 requests x 64 tokens) to long-form generation (36 x 256), adaptive draft length cuts latency substantially. Figure 2 breaks down these gains at draft length d=10 across the four datasets. The short-context benchmarks - Alpaca, SQuAD, and Coding - deliver consistent 35–45% speedups under both greedy (temp=0) and stochastic sampling decoding (temp=0.7, not shown). For the long-form dataset, while adaptive still provides sizeable gains, the savings drop to ~16–30%.
Why the gap? Speculative decoding fundamentally relies on the draft model tracking the target model’s distribution. As sequences grow longer, this alignment degrades. Our long-form benchmark averages 487 tokens per output (vs 128–256 for other datasets). The longer the context, the more cumulative errors compound, and acceptance rates fall accordingly5.
| Latency | ||
|---|---|---|
 |
 |
|
Figure 2 Adaptive draft length (d=10) achieves 35-55% latency reduction across datasets with Llama-3.1-8B-Instruct.
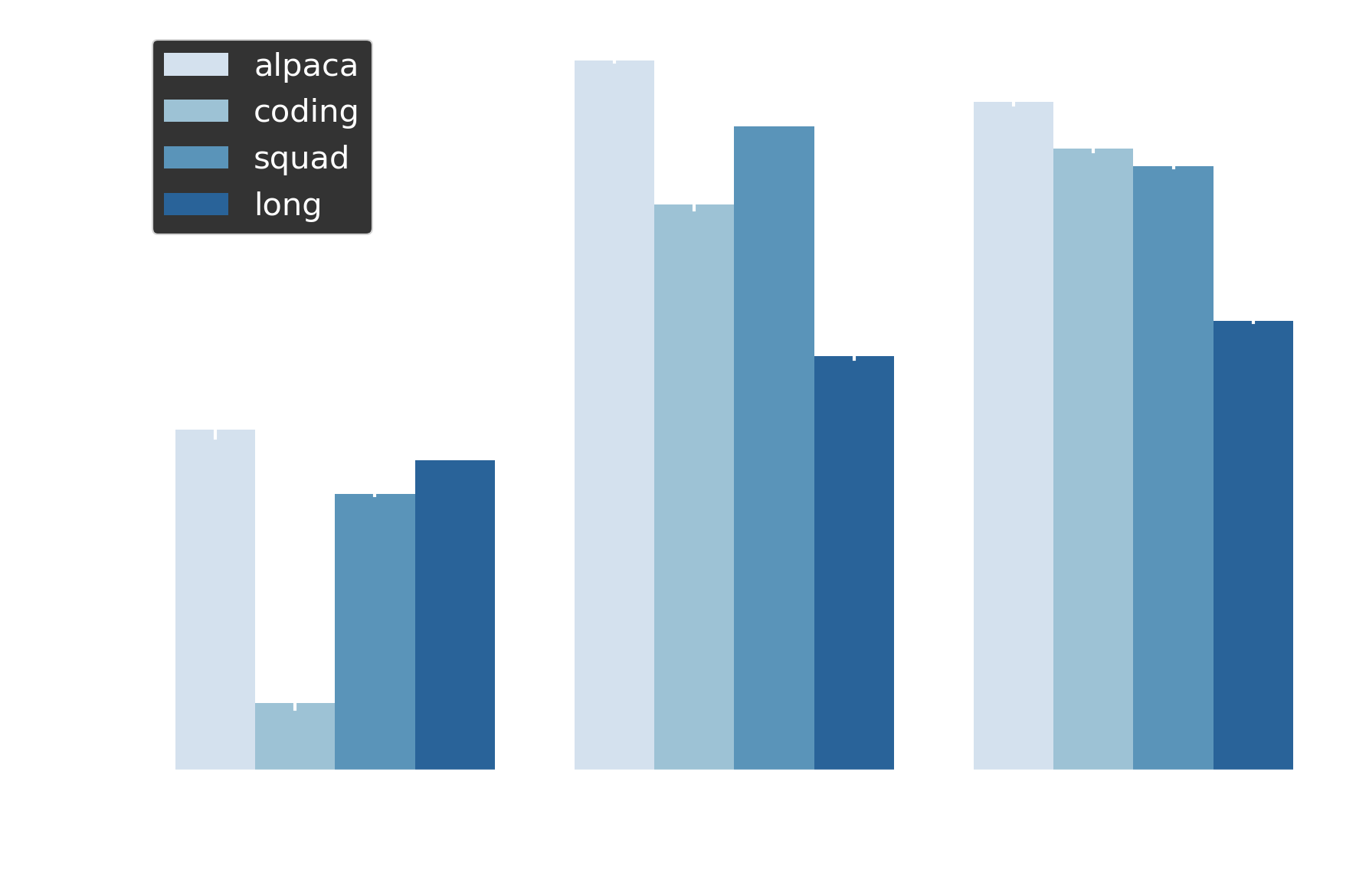
Next, we evaluated draft lengths of 5, 10, and 15 tokens on the 36 requests x 128 tokens configuration. These values span the typical deployment range: production systems conservatively use 3-5 tokens (Red Hat’s EAGLE3 at 3, NVIDIA’s reference configs at 5) to minimize wasted computation when drafts are rejected. Our experiments also tests draft lengths beyond this range, as some implementations suggest 8-10 and even 18-32 for methods like suffix decoding.
At d=5, adaptive speculation yields less savings across the board, which is logical as there are fewer possible ways to dynamically reduce K. The benefit does appear to saturate after d=10. We observe task-specific phenomena as well. As noted above, long-form generation maintains modest 16–30% speedups across all lengths, limited by fundamental acceptance rate degradation at extended sequences.
Coding presents a rather unique case compared to the other short form datasets. At d=5 there is minimal improvement (~4%), but d=10 unlocks 35% speedups. We suspect that this is because structured generation requires longer draft windows to amortize verification costs, a pattern documented in recent work6 showing that syntactic tasks need sufficient lookahead to capture token dependencies. We confirmed these results with the Llama 3.2 3B model as well.
| Llama 3.1 8B | Llama 3.2 3B |
|---|---|
 |
 |
Figure 3 Draft length sensitivity. Latency reduction confirms generalization across model scales (8B and 3B).
Ultimately, this variability explains why no single draft length works universally. Our adaptive approach sidesteps this problem by adjusting draft length per-request based on observed acceptance rates and task-specific requirements: fewer verification rounds when speculation is effective, and less wasted draft compute when it is not.
Confidence-based early exit: cutting speculative KV writes
The second component is confidence-based early exit, designed to reduce speculative KV writes. In standard speculative decoding, every drafted token writes to the KV cache. If a token is never accepted, that bandwidth was wasted. On hardware and workloads where decode is memory-bound, this is expensive.
Our goal is to avoid KV writes for speculative tokens that the draft model itself considers unlikely, while keeping (1) the loop structure compatible with CUDA graphs, and (2) the target model’s verification rule unchanged.
We’ve implemented the approach as follows:
- For each speculative step, we compute a simple confidence score per sequence (the maximum predicted token probability).
- We maintain a
continue_maskfor sequences that should keep writing KV. - On the next iteration, if a sequence has fallen below the confidence threshold, we mark its KV-write slot as padding.
- The KV-write stage treats padding slots as no-ops, so those tokens are skipped.
All sequences still execute the same control flow and only the data (which slots get written) changes. The target model still evaluates whatever drafts are produced, so we are not weakening correctness checks.
Why DRAM savings matter at scale
Early exit functions as a bandwidth control knob: terminate low-confidence speculations before writing full draft sequences to KV cache, trading local compute overhead for reduced memory pressure.
This matters because KV cache dominates production inference. At scale (large batches, long contexts), the decode phase is memory-bandwidth bound: research shows KV cache accounts for up to 73% of total memory in LLaMA-7B at batch=327, and over 50% of attention kernel cycles stall on data access delays8. Techniques that reduce KV cache bandwidth show 1.5-3.7× latency improvements in production (RocketKV, SQuat, Async KV prefetch).
Our early exit mechanism cuts DRAM writes by stopping speculation when confidence drops below threshold—fewer draft tokens generated means fewer KV cache entries written. In bandwidth-limited stacks (large models, long contexts, multi-tenant serving), this enables higher batch throughput and prevents OOM conditions. The 1-5% per-request latency cost translates to net system-level gains when memory bandwidth, not compute, is the bottleneck.
Bandwidth vs latency trade-off
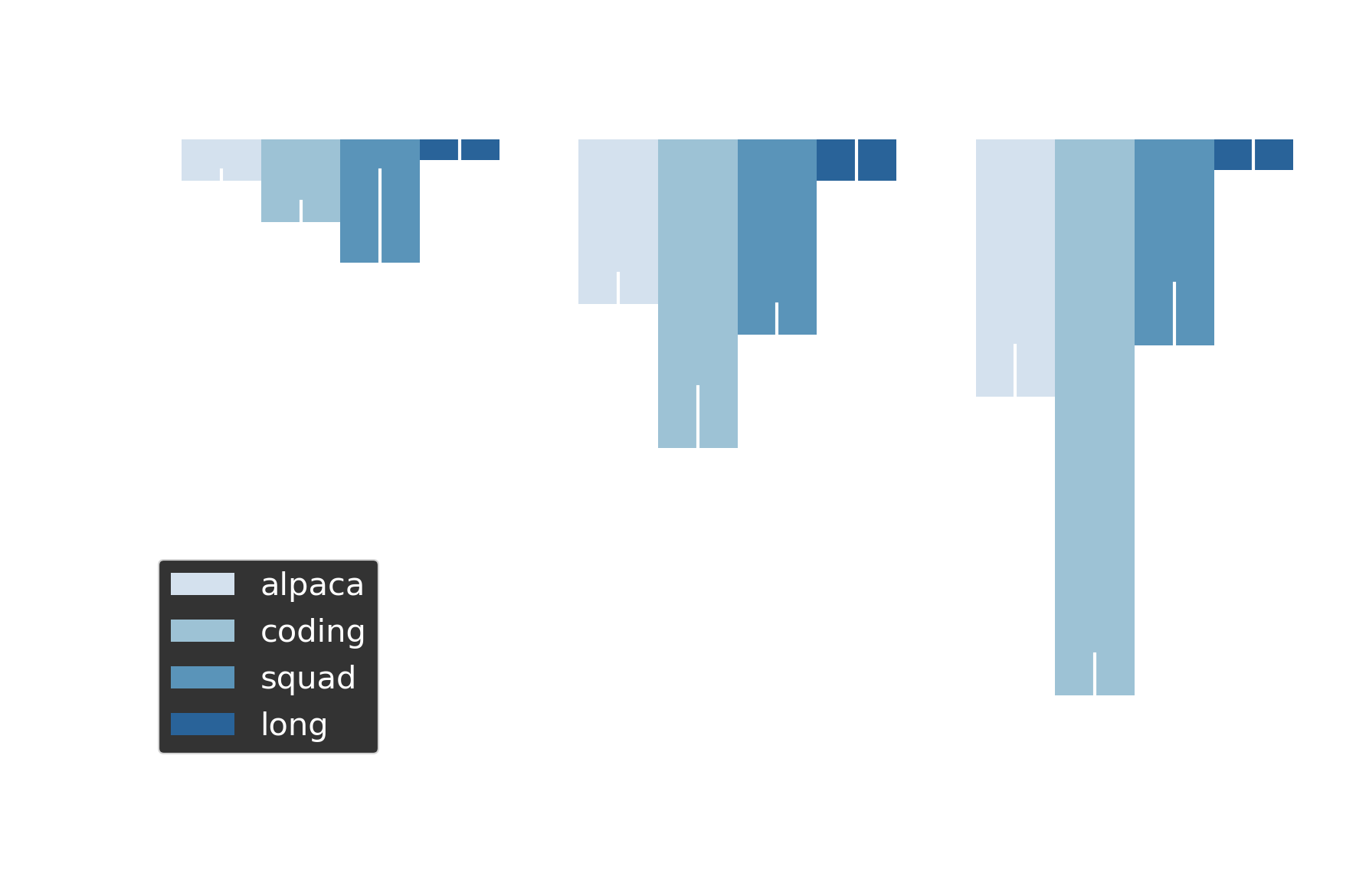
Figure 4 shows the bandwidth-latency trade-off across thresholds 0.3, 0.5, and 0.7. At threshold=0.5, early exit stops 50-65% of speculative tokens before KV cache writes, translating to roughly 50% fewer DRAM write operations in our NCU profiles. The cost: 1-3% higher end-to-end latency compared to no early exit.
This latency penalty emerges from the mechanics of speculation. When early exit terminates a draft sequence, fewer tokens are available for verification. Lower acceptance per round means more speculation rounds to generate the same output — and each additional round invokes the target model. On our compute-bound test hardware, this overhead dominates. But production deployments are bandwidth-bound at scale7, where 50% DRAM savings enables higher batch throughput. The mechanism is the same — and production regimes are precisely where bandwidth constraints bite.
| Latency | KV Writes Saved |
|---|---|
 |
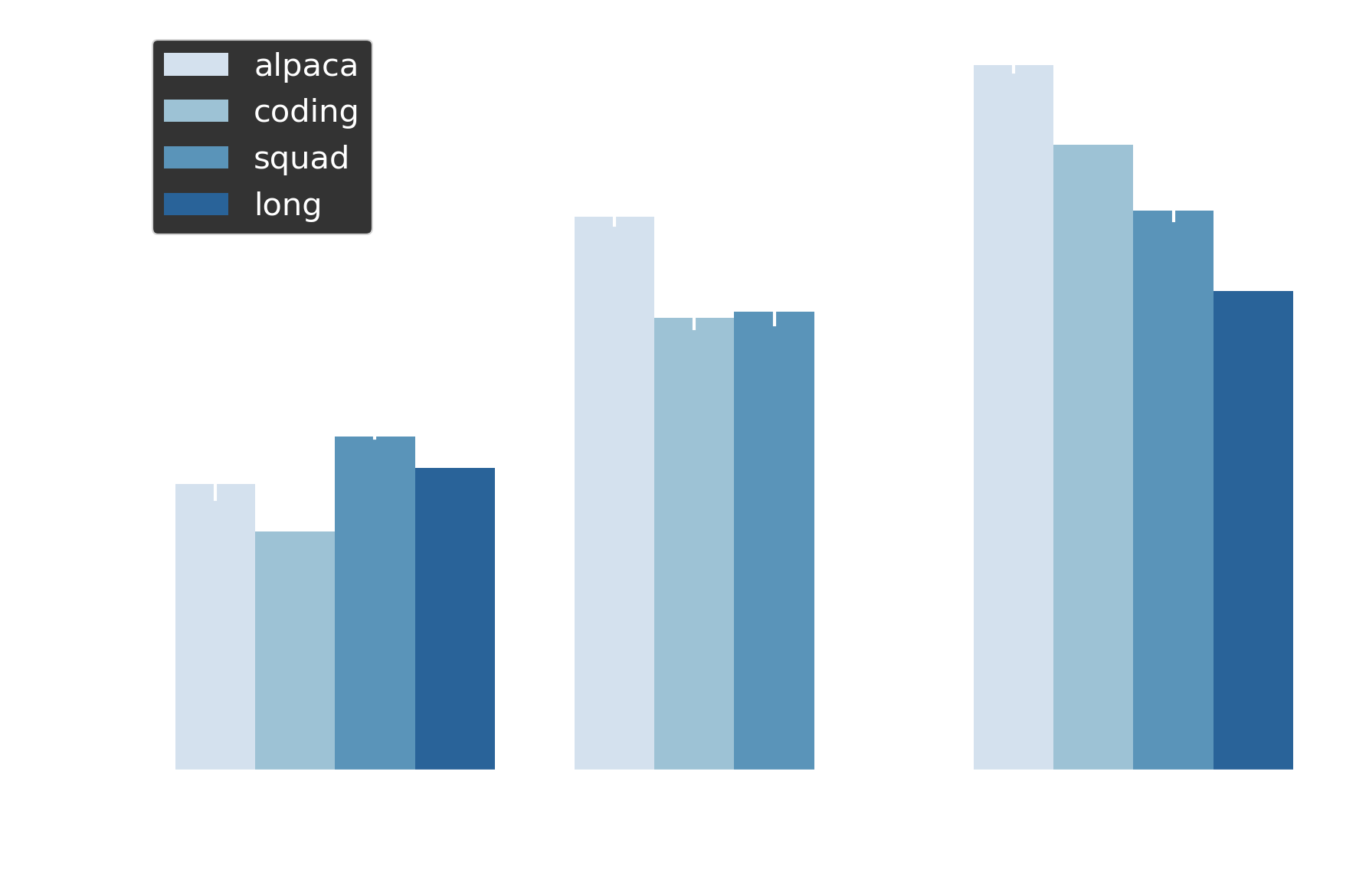 |
Figure 4 Early exit stops a threshold-proportional % of speculative tokens before KV cache writes. trades 1-3% latency for ~50% bandwidth reduction; coding shows steepest penalty (-5.4%) at threshold=0.7.
Figure 5 visualizes this relationship: higher stop rates correlate with larger latency penalties. Coding exhibits the steepest degradation at threshold=0.7 (73.7% stop rate, -5.4% latency), while other datasets show smaller penalties — structured generation suffers most when speculation is aggressively curtailed.
The optimal threshold will ultimately depend on deployment context. Bandwidth-limited production stacks benefit from aggressive early exit (threshold=0.5-0.7) to prevent OOM and enable larger batches. Compute-bound scenarios favor conservative thresholds (0.3) or disabling early exit entirely. Our implementation exposes threshold as a tunable parameter for operators to match their hardware constraints.
| Latency vs Bandwidth Trade-Off | ||
|---|---|---|
|
 |
|
Figure 5 Higher stop rates correlate with larger latency penalties on compute-bound hardware; optimal threshold depends on deployment context (Llama-3.1-8B-Instruct @ k=10).
Maintaining output semantics and quality
Elastic Speculation necessarily changes which speculative tokens are proposed and accepted, so we do not expect or intend to achieve exact bitwise-identical outputs. However, we do still want to ensure the overall quality and correctness of the output semantics. After all, what’s the point of speeding up inference if all you get out is non-sensical?
To quantify this difference, we systematically evaluated the exact outputs from adaptive draft length and early exit on (elastic speculation) against standard speculative decoding (fixed-length k). We also compared both against vLLM’s no-spec target model only to understand the relative semantic similarity and to ensure elastic speculation keeps our outputs in the same semantic regime.
Specifically, we evaluated the outputs under the following three criteria:
BERTScore F1(token-level semantic similarity)cosine similarity(sentence-level via Sentence-BERT similarity)- and a
reward model quality score(human preference alignment)
BERTScore F1 (Context-aware token alignment)
BERTScore measures semantic equivalence by comparing contextualized token embeddings from BERT-family models. Unlike surface-level string matching, it captures whether two texts convey the same meaning even with different wording.
How it works: The metric computes token-level similarity using contextual embeddings from microsoft/deberta-large-mnli9, then aggregates via precision, recall, and F1-score. Each token in the candidate text is matched to its most similar token in the reference text based on cosine similarity in embedding space.
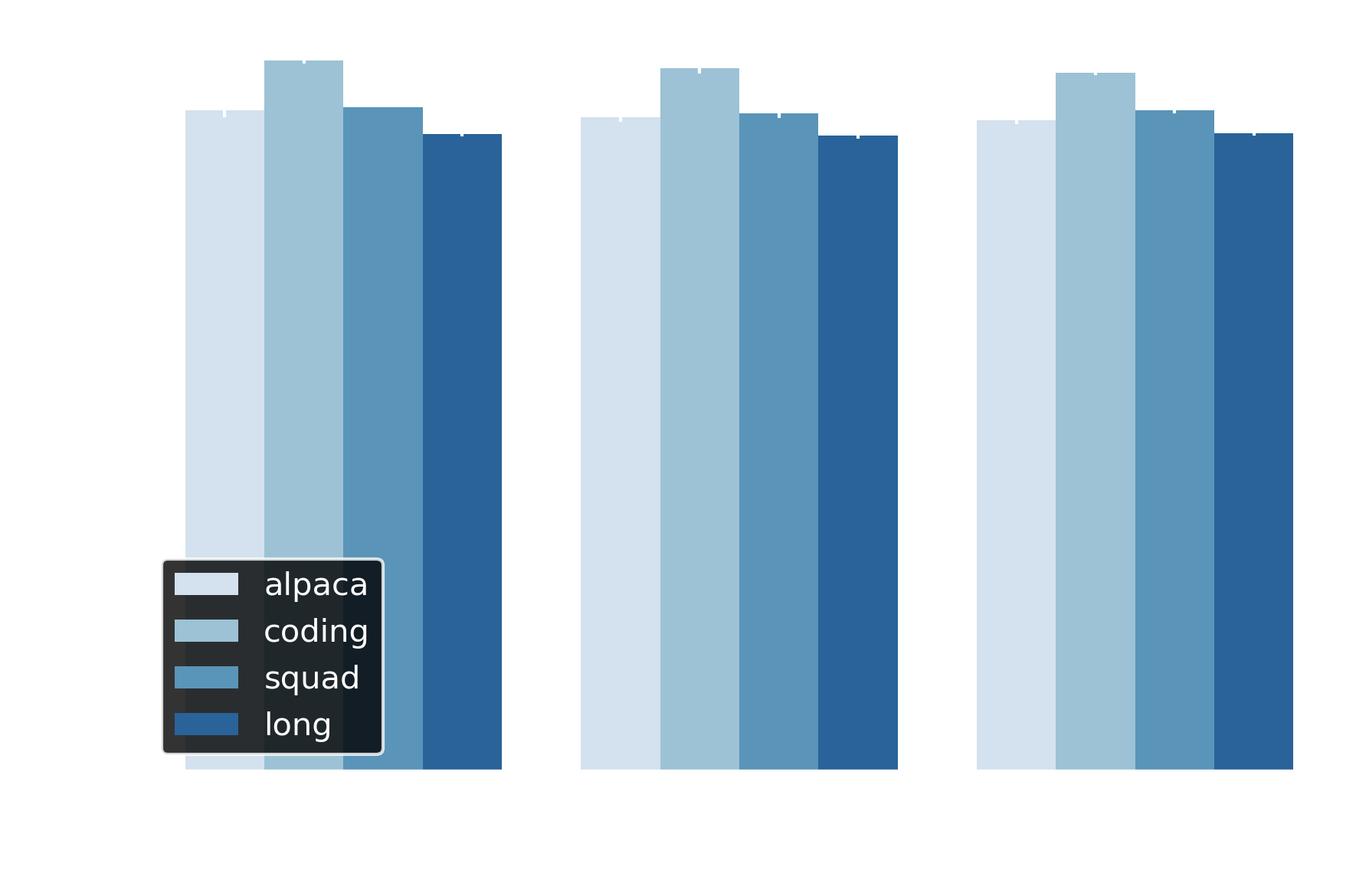
Both adaptive draft length and early exit maintain semantic fidelity: BERTScore F1 ranges from ~0.89 to 0.94 across all experiments. This places outputs well into the semantic equivalence regime—above the 0.90 threshold where texts convey identical meaning. For context, scores of 0.85-0.90 indicate paraphrase-level similarity, while values below 0.80 signal semantically different content.
| Adaptive (BERTScore F1) | Early Exit (BERTScore F1) |
|---|---|
 |
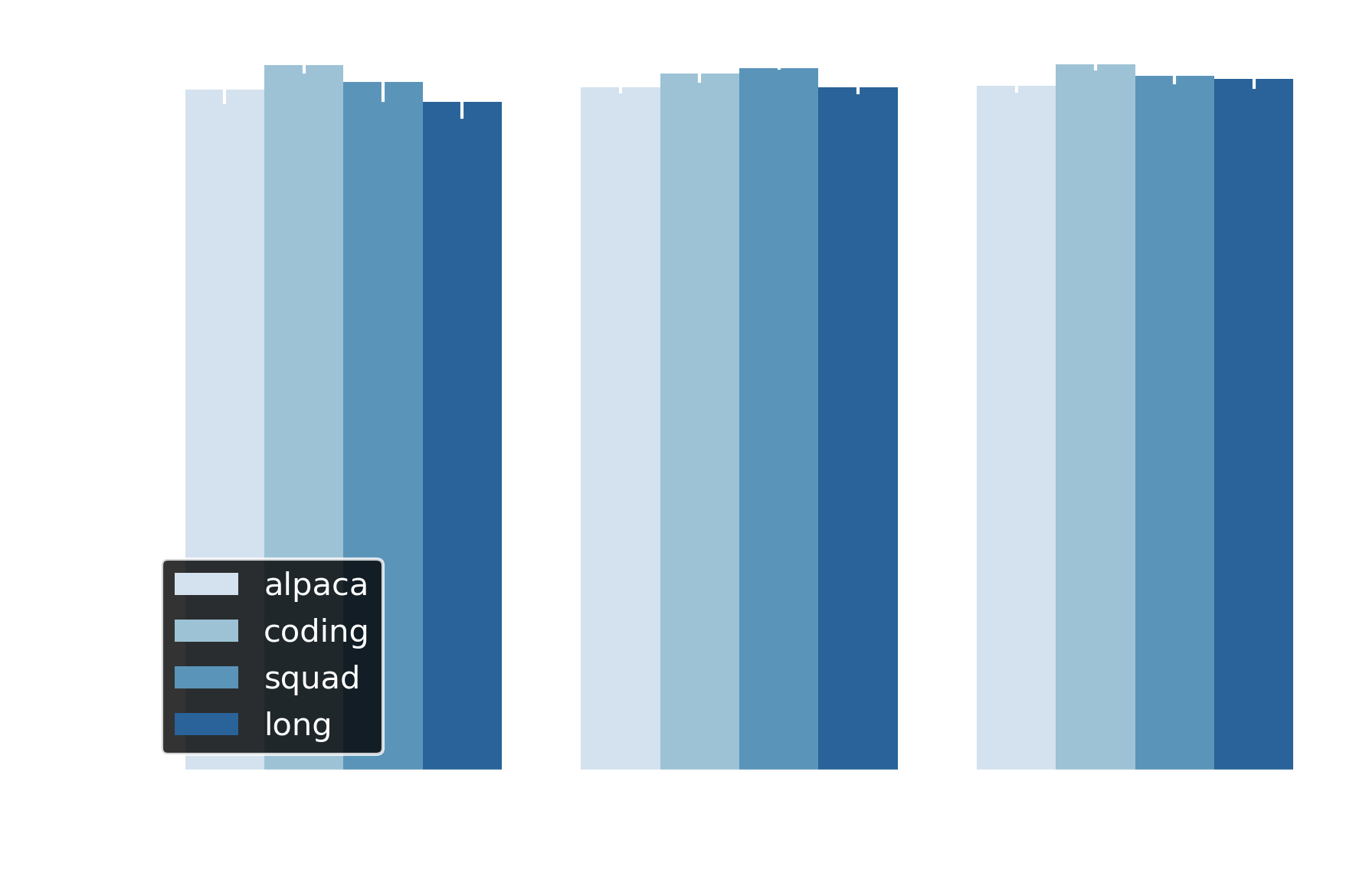 |
Figure 6 Adaptive draft length and early exit maintain BERTScore F1 >0.88 and F1 >0.95 respectively across all datasets, indicating semantic equivalence to baseline.
Cosine Similarity (Sentence-Level Embeddings)
Cosine similarity measures the angle between dense vector representations of complete sentences, capturing overall semantic content at the document level rather than token-by-token.
How it works: We encode each output using Sentence-BERT10 (all-mpnet-base-v2), which produces a single 768-dimensional vector per text. The cosine similarity between corresponding baseline and optimized outputs quantifies semantic alignment.
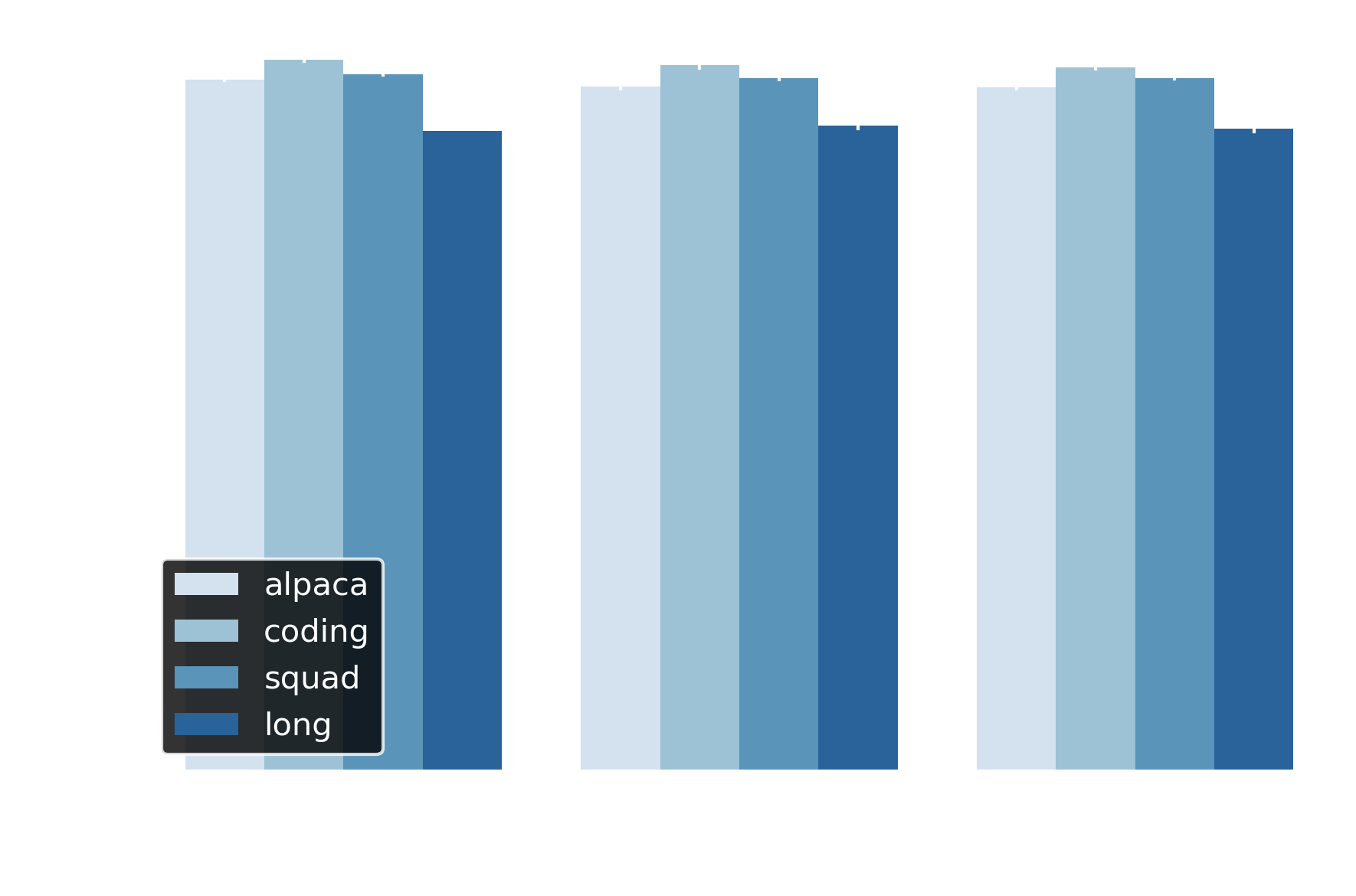
Cosine similarity between sentence embeddings confirms (and even exceeds) the BERTScore findings: adaptive draft length achieves >0.95 similarity for all datasets, with SQuAD and coding measuring over 0.97 (Figure 7). Early exit maintains >0.92 across thresholds. These scores place outputs well above the 0.85 threshold for semantic equivalence—effectively producing semantic duplicates of baseline outputs at the sentence level.
\[\text{cosine similarity}(u, v) = \frac{u \cdot v}{u \times v}\]where $u = \text{SentenceBERT}(\text{text}_1)$, $v = \text{SentenceBERT}(\text{text}_2) \in \mathbb{R}^{768}$
For reference, scores of 0.70-0.85 indicate paraphrases with similar meaning, while values below 0.60 signal semantically divergent content. Our results demonstrate that neither elastic technique introduces meaningful semantic drift.
| Adaptive (Cosine) | Early Exit (Cosine) |
|---|---|
 |
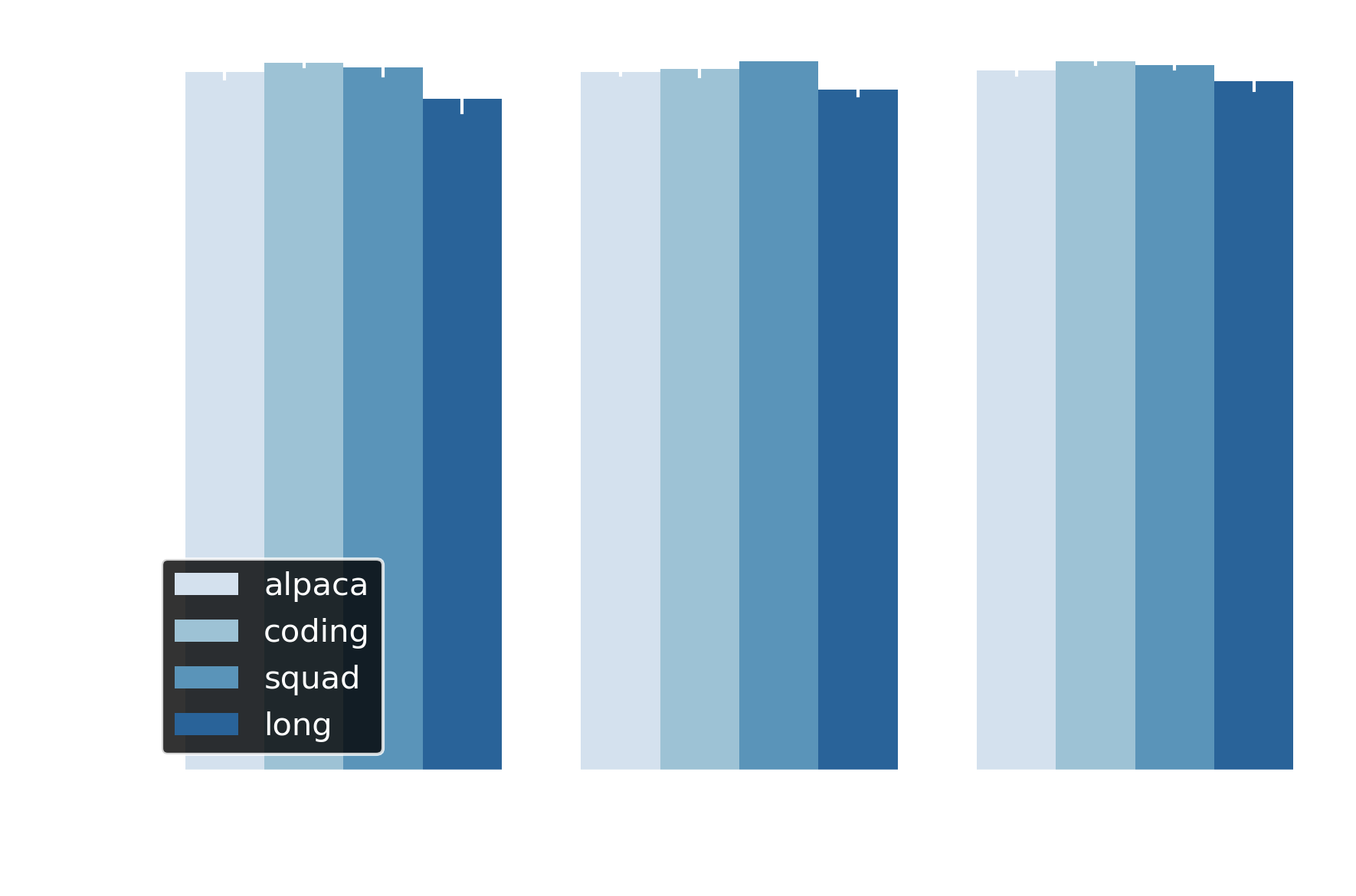 |
Figure 7 Adaptive draft length and early exit achieve >0.94 sentence-level similarity across all thresholds and datasets.
Reward Model Quality Score ∆ (Human Preference Alignment)
The reward model measures output quality based on human preference alignment, trained on datasets of human judgments about response quality. Unlike similarity metrics, it evaluates absolute quality rather than just semantic equivalence.
How it works: We used OpenAssistant/reward-model-deberta-v3-large-v211, a
DeBERTa-v3-largemodel fine-tuned on human preference data. The model scores each output on a continuous scale, predicting how humans would rate the response quality in terms of helpfulness, correctness, and coherence.
This particular model scores outputs on helpfulness, correctness, and coherence as a proxy for human-perceived quality. The model outputs unbounded logit scores (typically -5 to +5 range), where higher values indicate better quality.
Figure 8 plots the quality score delta: elastic speculation minus baseline speculation, with both compared against no-speculation runs. Values hovering near zero indicate equivalent quality. Adaptive draft length shows deltas within ±0.15 across all datasets, while early exit maintains ±0.2 across thresholds. Paired t-tests confirm no statistically significant difference (p > 0.85 across experiments). Mean absolute scores are baseline = -2.505, adaptive = -2.513 — both producing equivalently high-quality outputs from a human preference perspective.
| Adaptive (Quality ∆) | Early Exit (Quality ∆) |
|---|---|
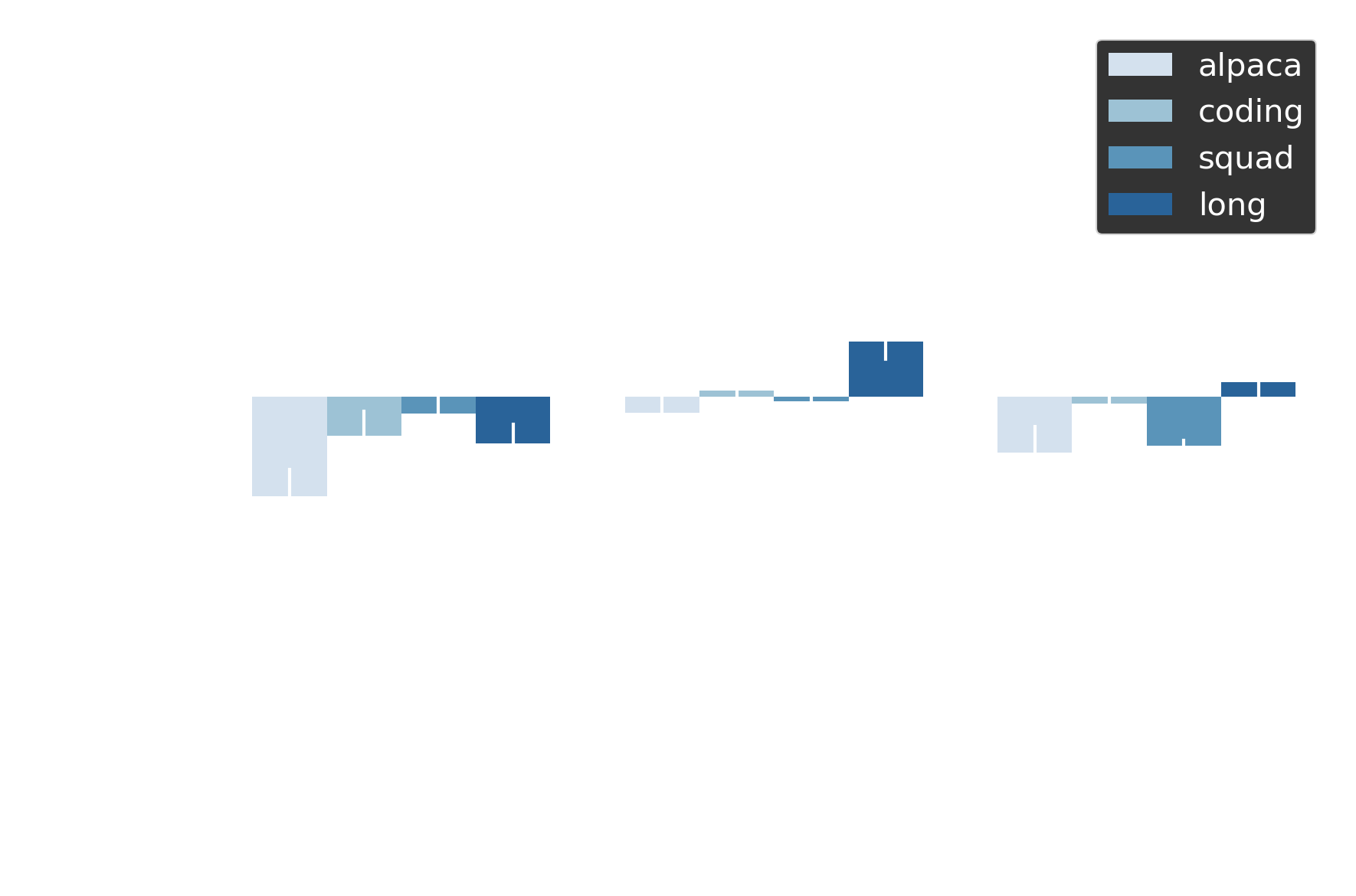 |
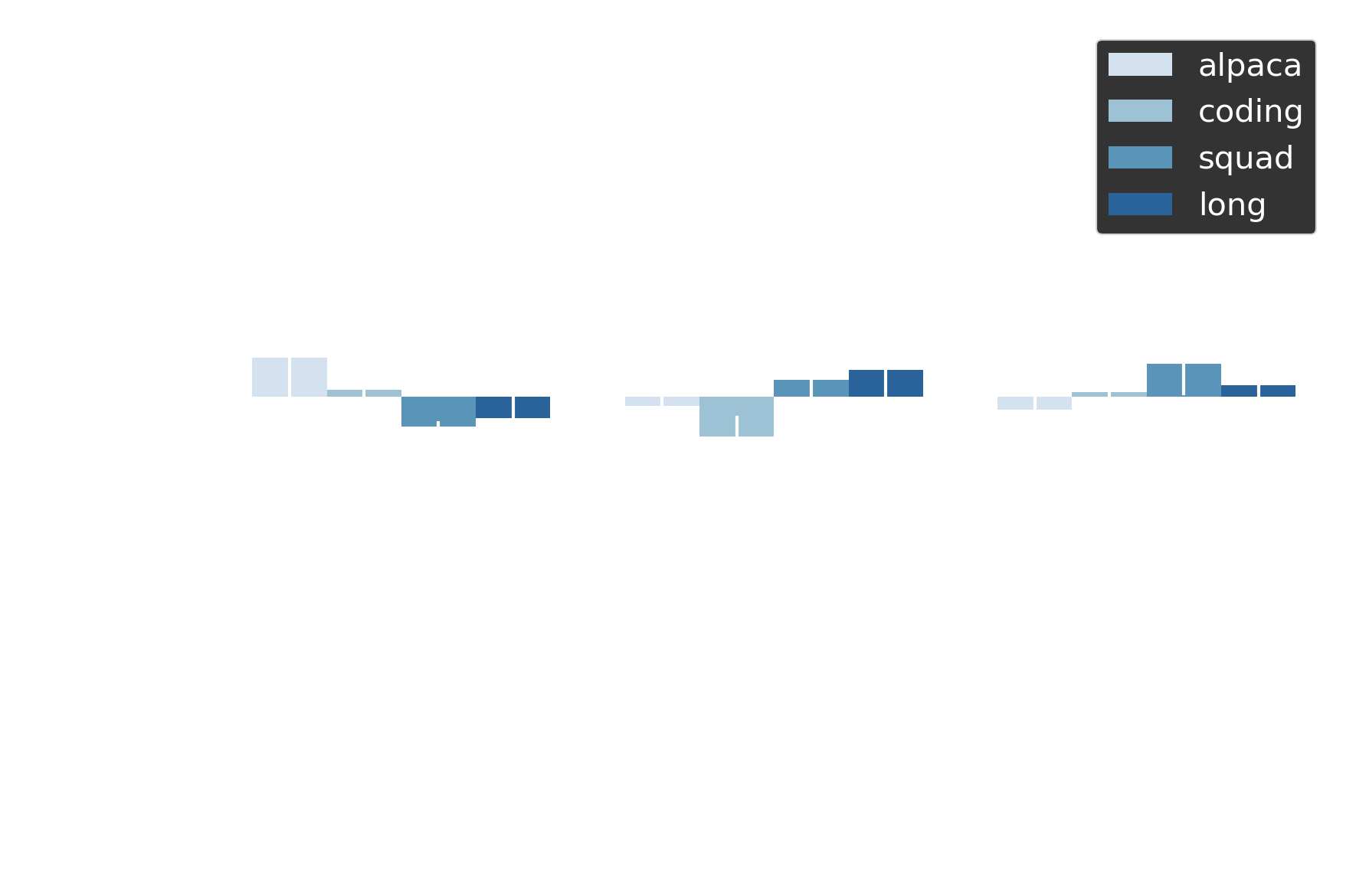 |
Figure 8 Quality deltas within ±0.15 confirm elastic speculation preserves human-perceived output quality; no statistically significant difference from baseline speculation (p>0.85).
Across all three metrics, elastic speculation preserves semantic quality. BERTScore >0.94, cosine similarity >0.95, and reward model deltas within ±0.2 confirm outputs match baseline speculation in both token-level fidelity and human-perceived quality.
To understand what “acceptable drift” looks like, we measured how much baseline speculation diverges from no-speculation runs. This gives us a reference: if speculation itself introduces some semantic variance, elastic variants should stay within that same range. They do — elastic spec vs. no-spec shows comparable deltas to baseline spec vs. no-spec (not shown). Our optimizations don’t add drift beyond what standard speculation already introduces. Finally, the 3B model replicates these findings across all metrics and conditions (not shown).
Note that the results shown use temperature=0.0. At temperature=0.7, scores drop for both baseline and elastic variants to similar degrees (not shown) — that’s just the nature of making using sampling based generation. Your outputs get a little spicy but elastic is no worse than baseline speculation.
Concluding Remarks
Elastic Speculation makes speculative decoding responsive by adapting to workload characteristics and hardware constraints in real time. In our tests, that means up to ~20-50% lower latency versus fixed-length K from adaptive draft length, and a proportional reduction in speculative KV writes based the selected threshold for confidence-based early exit. It changes how tokens are generated, not necessarily the meaning of what gets generated, staying within the same semantic regime as standard speculative decoding in the recommended settings.
We are preparing an vLLM PR so you can try Elastic Speculation in your own deployments, tune it for your workloads, and see how it behaves at your scale. Please feel free to share your findings and/or implementations for other frameworks!
Citation
Please cite this work as:
Zhao, Ben and Iluvatar Labs, "Elastic Speculation: Adaptive Draft Length and
Confidence-Based Early Exit", Iluvatar Labs Blog, Nov 2025.
-
Leviathan, Y., Kalman, M., & Matias, Y. (2023). “Fast Inference from Transformers via Speculative Decoding”. Proceedings of the 40th International Conference on Machine Learning (ICML 2023), 19274-19286. arXiv:2211.17192 ↩
-
Li, Y., Wei, F., Zhang, C., & Zhang, H. (2024). “EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”. Proceedings of the 41st International Conference on Machine Learning (ICML 2024). arXiv:2401.15077 ↩
-
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., & Stoica, I. (2023). “Efficient Memory Management for Large Language Model Serving with PagedAttention”. Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP ‘23). arXiv:2309.06180 ↩
-
Kwon et al. (2023) show that KV cache accounts for up to 73% of total memory in large-batch inference, with memory bandwidth becoming the primary bottleneck during decoding. ↩
-
Miao, X. et al. (2024). “Draft Model Knows When to Stop: A Self-Verification Length Policy for Speculative Decoding”. arXiv:2411.18462. The paper demonstrates that speculative decoding performance degrades as input length grows due to reduced draft accuracy. ↩
-
Chen, C., Borgeaud, S., Irving, G., Lespiau, J.-B., Sifre, L., & Jumper, J. (2023). “Accelerating Large Language Model Decoding with Speculative Sampling”. arXiv:2302.01318 ↩
-
Sheng, Y., Cao, S., Li, D., Hooper, C., Lee, N., Yang, S., Chou, C., Zhu, B., Zheng, L., Keutzer, K., Gonzalez, J. E., & Stoica, I. (2024). “S-LoRA: Serving Thousands of Concurrent LoRA Adapters”. arXiv:2311.03285 ↩ ↩2
-
Kim, J., Lee, M., & Kim, S. (2024). “Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference”. arXiv:2503.08311 ↩
-
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2020). “BERTScore: Evaluating Text Generation with BERT”. Proceedings of the 8th International Conference on Learning Representations (ICLR 2020). arXiv:1904.09675 ↩
-
Reimers, N., & Gurevych, I. (2019). “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP-IJCNLP), 3982-3992. arXiv:1908.10084 ↩
-
OpenAssistant/reward-model-deberta-v3-large-v2. Available at https://huggingface.co/OpenAssistant/reward-model-deberta-v3-large-v2. ↩